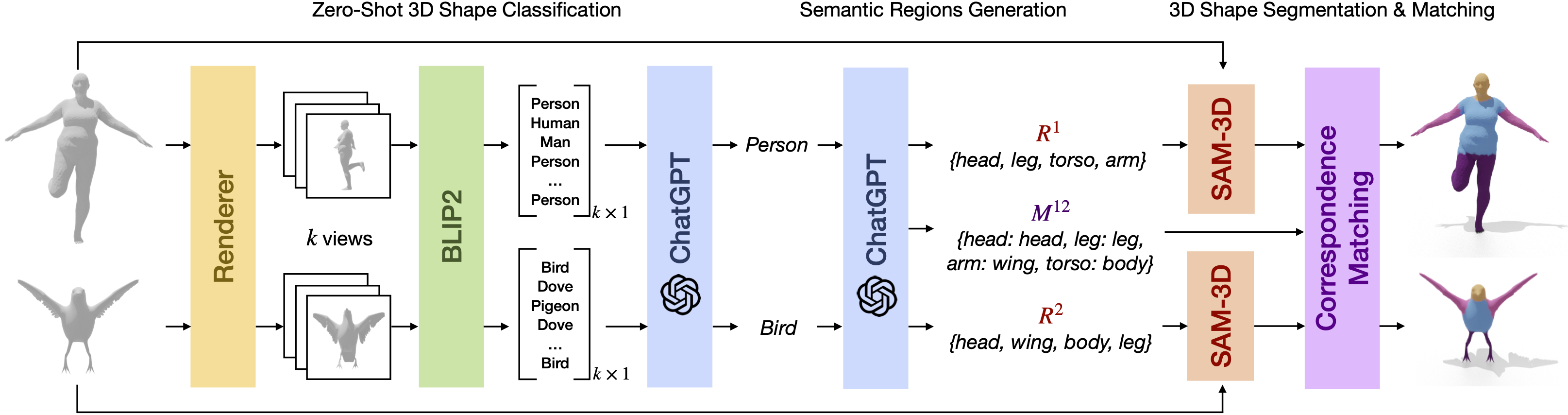
We propose a novel zero-shot approach to computing correspondences between 3D shapes.
Existing approaches mainly focus on isometric and near-isometric shape pairs (e.g., human
vs. human), but less attention has been given to strongly non-isometric and inter-class
shape matching (e.g., human vs. cow). To this end, we introduce a fully automatic method
that exploits the exceptional reasoning capabilities of recent foundation models in language
and vision to tackle difficult shape correspondence problems. Our approach comprises
multiple stages. First, we classify the 3D shapes in a zero-shot manner by feeding rendered
shape views to a language-vision model (e.g., BLIP2) to generate a list of class proposals
per shape. These proposals are unified into a single class per shape by employing the
reasoning capabilities of ChatGPT. Second, we attempt to segment the two shapes in a
zero-shot manner, but in contrast to the co-segmentation problem, we do not require a mutual
set of semantic regions. Instead, we propose to exploit the in-context learning capabilities
of ChatGPT to generate two different sets of semantic regions for each shape and a semantic
mapping between them. This enables our approach to match strongly non-isometric shapes with
significant differences in geometric structure. Finally, we employ the generated semantic
mapping to produce coarse correspondences that can further be refined by the functional maps
framework to produce dense point-to-point maps. Our approach, despite its simplicity,
produces highly plausible results in a zero-shot manner, especially between strongly
non-isometric shapes.